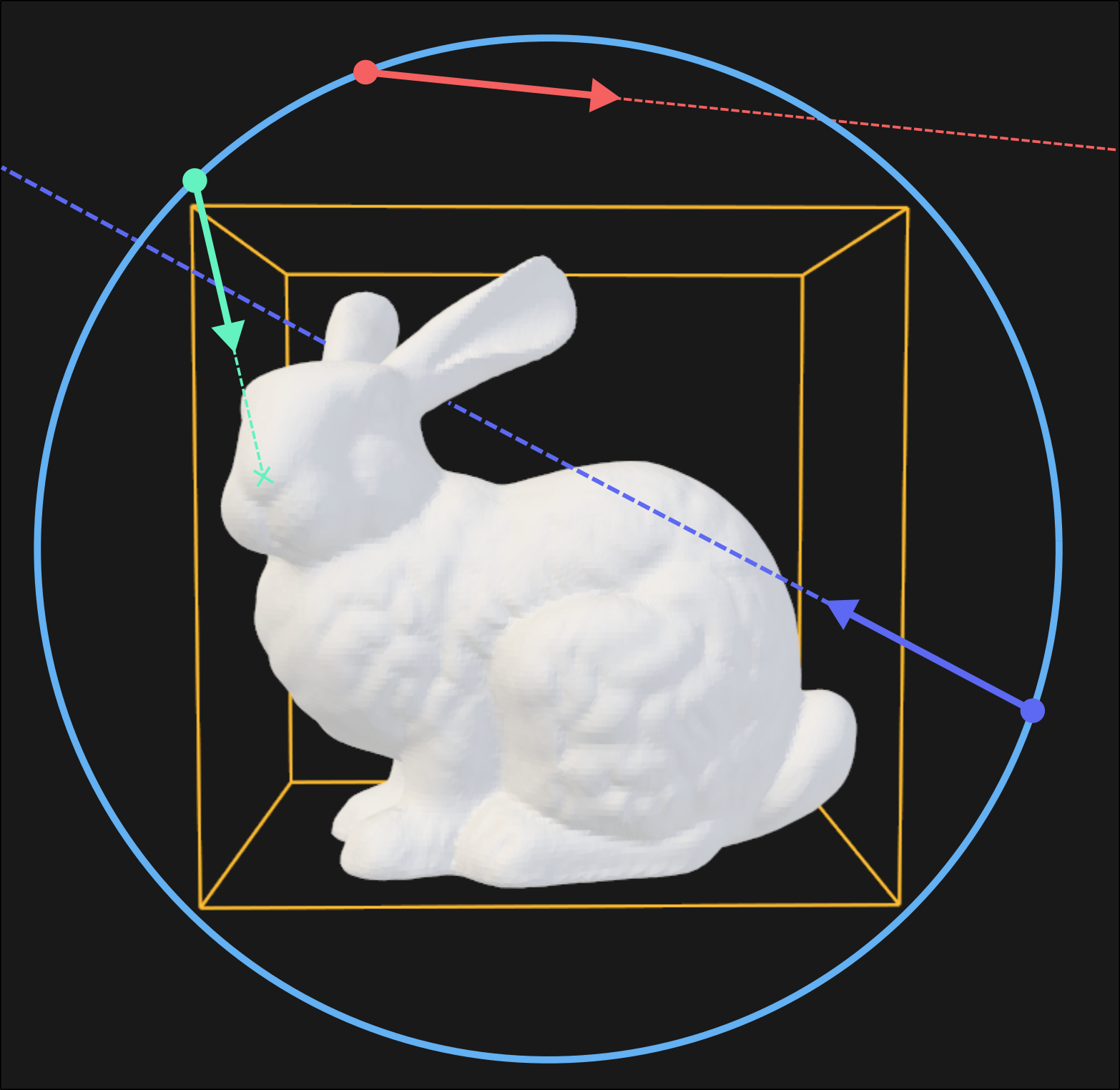
To improve my Bounding Box Hierarchy implementation, I implemented a benchmarking scheme and tweaked the BBH tree traversal algorithm. Instead of a static traversal path, the child to visit first is picked based on the ray direction.
Benchmarking
Casting a ray is the single most important operation in my path tracing renderer. Thousands of rays are needed per pixel to calculate the lighting, so it is a natural point to start optimizations. As a low hanging fruit I decided to look into how the BBH is traversed.
To be able to quantify the improvements I used the following approach:
- Determine a sphere around the benchmarked mesh, the center is the center of the mesh, the radius is hand tuned.
- Uniformly randomly generate points on the sphere (
p), these will be the starting points of the rays. - Uniformly randomly generate a ray direction on the hemisphere facing inwards the sphere from
p. - Trace the rays and record how many box and triangle tests are performed.
Re-using the sampling functions from my path tracer makes the implementation convenient:
const auto dir0 = uniformSphereSample(rng);
const auto dir1 = uniformSphereSample(rng);
const auto r = radius * 1.1f;
const auto p0 = dir0 * r + center;
const auto p1 = (dir1 - dir0) * r + center;
const auto ray = Ray{.p = p0, .v = (p1 - p0).normalized()};
const auto intersection = rayMeshIntersectionTest(ray, tris, bench);
if (intersection.has_value())
{
bench.registerTriangleHit();
}
Two directions are chosen, one dictates the starting point of the ray, the other the offset of the direction. This way the ray is biased to head towards the center of the object more often and thus hit it more often.
An interesting bit of C++/CUDA here is how I made the benchmarking zero cost in production. The ray intersection function is templated on a Benchmark type. This type is used to record different events.
template <typename T>
concept Benchmark = requires(T b) {
b.recordTriangleHitTest();
};
template<Benchmark B>
Intersection rayMeshIntersectionTest(Ray ray, TriangleMesh tris, B &bench)
{
Intersection best;
for (const auto &triangle : tris)
{
bench.recordTriangleHitTest();
rayTriangleIntersectionTest(ray, triangle, best);
}
return best;
}
Using a concept ensures that I get good code completion suggestions and only appropriate types can be used for benchmarking. During benchmarking a real counter is passed in:
struct BenchmarkMode
{
int triangleHitTests = 0;
void recordTriangleHitTest() { ++triangleHitTests; }
};
In production however a completely empty struct is used:
struct ProductionMode
{
void recordTriangleHitTest() {}
};
Since my CUDA code is compiled as a single unit, all these definitions are available to the compiler that happily inlines, then eliminates empty member functions. The actual bench object is also empty and can be eliminated. Although this is not guaranteed, an optimizing compiler with full access to how the variable is used should do a good job here.
Current numbers:
== Benchmark Finished ==
Number of rays: 10'000'000
Triangle hits: 7314381 (73.1438%)
Triangle tests: 47570090 (4.75701/ray)
BBox tests: 1162815978 (116.282/ray)
== Benchmark Reported ==
I picked the sphere radius so that about 2/3 rays hit the bunny. The ratio of triangle to box hit tests is great, my triangle hit test is much more expensive than the box test. However this can be greatly improved using a few tricks.
Tweaks
First of all, when a triangle intersection is found, all subsequent box hits that happen farther can be immediately discarded:
if (bboxHit.has_value())
{
if (!best.has_value() || bboxHit->t < best->t)
{
// Proceed with children or check triangle inside if leaf
}
}
This already reduces the tests by about 25%:
== Benchmark Finished ==
Number of rays: 10'000'000
Triangle hits: 7314381 (73.1438%)
Triangle tests: 33641847 (3.36418/ray)
BBox tests: 911012120 (91.1012/ray)
== Benchmark Reported ==
The Bounding Box Hierarchy tree is constructed using splits. During these splits the triangles are divided into a “left” and a “right” side, based on the currently split axis.
Rays traveling “to the right” have a higher chance to hit a triangle in the “left” child and vice-versa. Therefore dynamically choosing which child to descend into can further reduce the number of required tests.
Currently always the “left” child is picked first:

But instead picking the right child first would eliminate all unnecessary tests on the left side:

This is not always a beneficial change, since the ray could actually be heading to a triangle in the farther child, but in general it is expected to benefit the traversal.
Implementing the ray direction heuristic
Since the traversal is now dynamic and depends on the input ray, I need to keep track of which child has been processed, to know which to descend into second. Keeping a stack on the GPU is costly and slow but luckily this can be encoded with one bit of information per level: whether the currently processed child is the “near” child.
Testing if a ray is headed left or right depends on the depth, since I split in an alternating fashion:
bool rayPointsToRight(const Ray& ray, uint32_t depth)
{
uint32_t axis = depth % 3;
if (axis == 0) return ray.v.x > 0.0f;
if (axis == 1) return ray.v.y > 0.0f;
return ray.v.z > 0.0f;
}
int nearChild(const Ray& ray, uint32_t depth, const BBHNode &node)
{
if (rayPointsToRight(ray, depth))
{
return node.left_child;
}
return node.right_child;
}
// farChild similarly to nearChild
Using this primitive the traversal heuristic can be implemented. The loop has three parts: testing the current node, descending to the near child, and ascending until a new far child is found:
uint32_t bit_trail = 0;
uint32_t depth = 0;
int current_index = 0;
while (current_index >= 0 && current_index < bbh.nodes.size())
{
const auto &node = bbh.nodes[current_index];
const auto bboxHit = testBoxIntersection(node.box, ray);
if (bboxHit.has_value())
{
if (!best.has_value() || *bboxHit < best->t)
{
if (node.isLeaf())
{
// Test all triangles in leaf box
}
else
{
// Descend to "near" child
continue;
}
}
}
// Ascend until a node needs its "far" child to be processed
}
Descending into the near child:
const auto near_child = nearChild(ray, depth, node);
bit_trail &= ~(1u << depth);
current_index = near_child;
depth++;
The bit_trail variable encodes the path to the current node in the BBH tree. Upon descent, the appropriate bit is marked to keep the trail up to date.
Traversing upwards is done with a loop that breaks when the root node is reached or when the far child needs processing.
while (true)
{
if (current_index == 0) {
current_index = -1;
break;
}
const auto parent_index = bbh.nodes[current_index].parent_index;
const auto &parent = bbh.nodes[parent_index];
depth--;
const auto far_child_visited = bit_trail & (1u << depth);
if (!far_child_visited)
{
// Descend into far child, similar to near child descent
break;
}
else
{
current_index = parent_index;
}
}
And then the skip_index from the previous implementation is no longer needed.
Results
Both tweaks reduce the needed tests substantially. Since the ray - scene intersection test is the foundation primitive of the path tracing engine, these gains translate to significant speedups.
I tested the two tweaks with three meshes:
- Stanford Bunny: 70'000 triangles
- Blender Suzanne: 1'000 triangles
- Icosahedron: 20 triangles
The benchmark results look great, the required box and triangle tests decreased by 50-65% in the different cases:
Triangle tests per ray
| Model | Baseline | +Early cutoff | +Ray dir. heuristic |
|---|---|---|---|
| Bunny | 5.92 | 3.77 | 2.14 |
| Monkey | 7.20 | 4.72 | 2.90 |
| Ico | 5.76 | 3.87 | 2.36 |
BBox tests per ray
| Model | Baseline | +Early cutoff | +Ray dir. heuristic |
|---|---|---|---|
| Bunny | 136.43 | 94.84 | 57.93 |
| Monkey | 91.00 | 65.76 | 45.22 |
| Ico | 30.73 | 23.42 | 17.60 |
Conclusion
It was a fun step to tweak the tracing algorithm to use fewer box and triangle tests. While this does not make the tests themselves faster, it results in 50–65% fewer tests.
I am happy with where I got with the tracing algorithm in general, next up I will look into optimizing the actual code for the GPU!