The rendered images look good but it takes an awful lot of time to create them. Adding more effects later will make it even slower, so I want to take a look into using more of my computer’s resources to render.
Single-threading
The renderer currently uses a single CPU core. To assess the speed gains I wrote some code to count the number of ray casts performed per second.
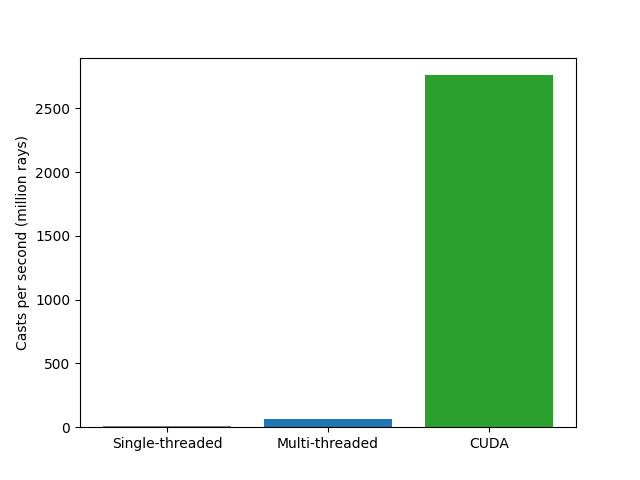
In the single-threaded version that works out to be 9.1 million ray casts per second.
Multithreading
The CPU in my laptop has 20 physical cores, I can make use of that! And it’s pretty simple to do even. The current sampling loop
for (int y=0;y<height;++y) {
for (int x=0;x<width;++x) {
for (int i=0;i<iterations;++i) {
// sample random path from pixel (x,y)
}
}
}
is independent for pixels, so I can replace the outer loop over the height with a parallel for loop:
parallel_for(height, [](int y){
for (int x=0;x<width;++x) {
for (int i=0;i<iterations;++i) {
// sample random path from pixel (x,y)
}
}
});
Where parallel_for spawns enough threads to engage all cores of the CPU and splits the work evenly between them. Here’s the source code for it for completeness:
parallel_for source code
template <typename F>
void parallel_for(int range, const F &func) {
auto num_threads = std::thread::hardware_concurrency();
if (num_threads == 0) num_threads = 1;
int chunk_size = (range + num_threads - 1) / num_threads;
std::vector<std::jthread> threads;
for (int t = 0; t < num_threads; ++t) {
int start = t * chunk_size;
int end = std::min(start + chunk_size, range);
threads.emplace_back([start, end, &func]{
for (int i = start; i < end; ++i) {
func(i);
}
});
}
}
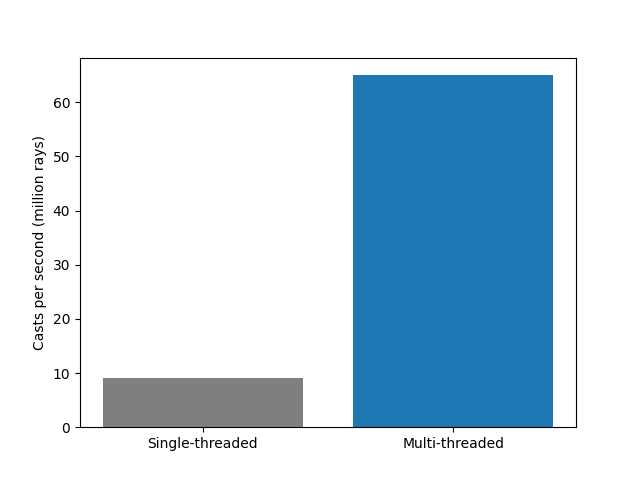
I got a nice 7x speedup. It’s probably “only” get a 7x even though I have 20 cores because of poor caching. I don’t want to spend time on optimizing this now, just appreciate the cheap speedup.
A few notes:
- I had to create a random number generator pool, otherwise the threads would keep recreating them and not calculate anything new.
- I used an LLM to generate the
parallel_forcode to save a few minutes, but instead I had to debug it for 10 minutes… - Threads could be reused if I made a pool for them too.
GPU + CUDA
I happen to have an Nvidia GPU in my PC as well. This has an order of magnitude more cores than my CPU, which is the limiting factor for now.
Moving the entire computation stack to CUDA was not too hard, since I have been using std::variant and std::visit instead of inheritance, they work out of the box in CUDA code, after enabling constexpr functions.
To allow running my ray tracing functions, such as ray casting, checker board pattern etc I need to mark them as __host__ __device__, the preprocessor can help with that:
#ifndef __CUDACC__
#define __global__
#define __device__
#define __host__
#endif
#define HD __host__ __device__
Then I can just mark the helper functions with HD.
I pass around arrays of objects as std::span, which also works in CUDA out of the box.
The render loop over the pixel then turns into a CUDA scheduling:
dim3 dimBlock(16, 16);
dim3 dimGrid;
dimGrid.x = (resolution.width + dimBlock.x - 1) / dimBlock.x;
dimGrid.y = (resolution.height + dimBlock.y - 1) / dimBlock.y;
cuda_render<<<dimGrid, dimBlock>>>(resolution, camera, objects, materials, debug, ...);
I use 16x16 blocks because I expect the memory access to dominate the runtime and I pass in a lof of objects, hence the register usage will be too high to use 32x32. This way the block size is a comfortable multiple of the warp size and the core/SM count too.
To generate random number I use curand. Each pixel gets its own XORWOW random state and use that to generate new pseudo random numbers. XORWOW is not the most sophisticated or safest random number generator, but it’s blazing fast and uses little memory for its state.
Finally, counting the cast rays is done on a per pixel basis as well now, to avoid any form of synchronization. The results are aggregated when needed. Later on I want to add support for showing different statistics for each pixel, like number of ray casts and color variance.

A good 42x speedup compared to the multi-threaded version!
Ray cast distribution
As a bonus I plotted the number of ray casts for each pixel.

The image is scaled, so a perfectly white pixel means it had the most rays cast on the image.
The only way a pixel would receive less rays right now is that the path tracing escapes the box, in that case the tracing is terminated early.
Conclusion
This was a really fun part of the project, because CUDA supports so much of modern C++. The effort to the speedup ratio is really satisfying.
The code is by no means optimal for the GPU currently so there is more speed to be had. Before optimizing the code I want to add more effects and support triangle meshes.